C++ Coroutine
Coroutine이란?
프로그램이 실행될때 불려지도록 만들어진 프로그램의 중심이 되는 일련의 코드들을 Main Routine(메인 루틴) 이라고 하며, Main Routine외에 다른 Routine들을 모두 Subroutine(서브루틴) 이라고 합니다. 그리고 진입하는 지점을 여러 개 가질 수 있는 Subroutine을 Coroutine(코루틴) 이라고 합니다. Coroutine은 호출한 Routine을 대등한 관계로 호출할 수 있기 때문에 다른 Routine의 종속관계가 아니라고 표현하기도 합니다.
C++에서는 main함수가 Main Routine이고 그 외에 다른 함수들은 모두 Subroutine이라고 볼 수 있습니다. 따라서 Coroutine은 함수 내에서 호출한 쪽을 다시 호출할 수 있고 다시 다른 Routine에서 함수의 중간 지점을 호출할 수 있는 것이라고 할 수 있습니다.

Main Routine과 Subroutine

Coroutine
Coroutine은 Thread와 비슷하다?
보통 Coroutine을 Thread와 비슷한 개념이라고 말하기도 하는데, 저는 이것이 Coroutine을 이해하기 어렵게 만든다고 생각합니다. 결과적으로 보면 비슷한면이 많습니다. Thread와 Coroutine 모두 자신만의 스택이 존재하고 실행 순서를 가집니다. 하지만 Coroutine은 Thread가 아닙니다.
Thread란 프로그램 내에서 실행되는 흐름의 단위를 말합니다. 모든 프로그램은 최소 하나의 Thread를 가지며, 이 Thread를 Main Thread(주 스레드)라고 합니다. 그리고 이 Main Thread에서 Main Routine이 불려집니다. Thread는 흐름의 단위이기 때문에 새로운 Thread가 만들어졌다는 것은 새로운 시간 흐름이 만들어졌다고도 볼 수 있습니다. 이렇게 프로그램은 여러 개의 Thread를 동시에 실행할 수도 있고, 이것으로 인해 일종의 흐름이 동시에 진행될 수 있습니다. 이러한 실행 방식을 Multithread(멀티스레드)라고 합니다.
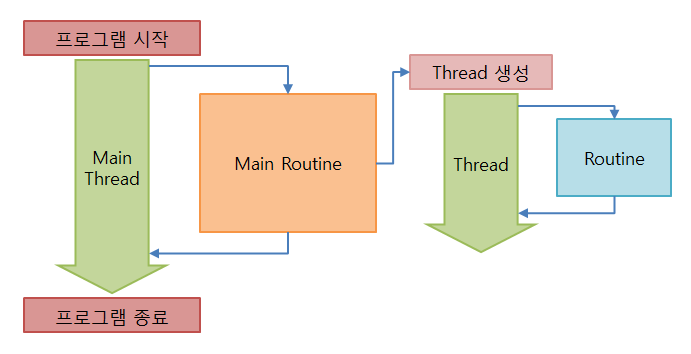
즉, 독립적인 시간 흐름을 가지고 Routine을 실행하는 것이 바로 Thread인 것입니다. 그래서 보통의 Routine들은 시작부터 끝까지 하나의 Thread에서 실행되지만 Coroutine은 호출자를 다시 호출할 수 있고 진입 지점을 여러 개 가질 수 있다는 특성 때문에 여러 Thread에서 하나의 Coroutine이 실행될 수 있습니다. 이러한 특성 때문에 Coroutine이 비동기 로직 처리에 유용하게 사용될 수 있습니다.

C++ 에서의 Coroutine
Coroutine을 지원하는 언어는 상당히 많지만 C++은 Coroutine을 정식으로 지원하지 않습니다. 하지만 C++에서 Coroutine을 사용하기 위한 많은 시도가 있었으며, 그 중 대표적으로 boost 라이브러리에 포함된 Coroutine(1.53 버전부터 포함)이 있습니다. boost는 Coroutine을 구현하기 위해 스택을 만들고 점프할 수 있는 기능을 가진 boost Context를 사용합니다.
Context Switching 비용이 너무 커서 부담스럽다?
Context Switching은 보통 Thread와 밀접한 관계를 가지고 있습니다. 위에서 Thread는 독립적인 시간 흐름을 가지고 Routine을 실행하는 것 이라고 했는데, Thread가 하나 존재한다면 Routine이 하나의 시간 흐름속에서 실행이 되는 것입니다. 그렇다면 이러한 Thread가 100개 존재한다면 어떻게 실행되어야 할까요?

100개의 Thread가 모두 독립적인 시간 흐름을 가지기 때문에 100개의 Routine이 모두 동시에 실행이 되어야 합니다. 하지만 우리가 보통 사용하는 컴퓨터 환경은 그렇게 동작하지 않습니다.
Routine은 어떠한 작업을 수행하기 위한 명령어들로 이루어져있는데 이 명령어들을 해석하여 연산하는 것이 CPU 입니다. CPU는 여러 개의 Core를 가지기도 하는데 이 Core 개수만큼 동시에 연산을 할 수 있다고 생각할 수 있습니다. 따라서 Core가 하나인 CPU이면 동시에 처리할 수 있는 연산은 하나입니다. 따라서 100개의 Thread가 동시에 연산되려면 100개의 Core가 필요한 것입니다.
그래서 우리가 흔히 사용하는 OS들은 OS가 Thread의 CPU 점유를 제어하여 실행될 수 있도록 합니다. 한정된 자원을 분할해서 수백개의 Thread가 동시에 실행될 수 있도록 하는 것입니다. 이 과정에서 Thread들은 CPU 자원을 차지하기 위해 경쟁을 하게 되고 그렇게 CPU 자원을 선점한 Thread가 Routine을 실행할 수 있는 것입니다. 이것이 Preemptive Multitasking(선점형 멀티태스킹)입니다.
Preemptive Multitasking에서는 어느 한 Thread가 CPU 자원을 독점할 수 없기 때문에 모든 Thread가 계속 경쟁을 해서 CPU 자원을 선점하게 되고, Thread가 CPU 자원을 선점하면 다른 Thread는 실행이 중단될 수 있습니다. 이렇게 CPU 자원을 선점하는 과정에서 이전에 CPU 자원을 사용하고 있던 Context의 정보를 저장하고 새로 선점한 Context의 정보를 가져오는 것을 Context Switching 이라고 합니다.
Context Switching은 독립적인 정보를 가지고 명령어를 실행하기 위해 생기는 현상입니다. Thread처럼 C++에서의 Coroutine은 독립적인 정보를 가져야 합니다. Routine이 중간에 빠져나갔다가 다시 호출되었을 때 이전에 Coroutine에서 생성한 로컬 변수나 연산들이 정상적으로 동작해야 하기 때문입니다. 그래서 C++에서의 Coroutine은 독립적인 Stack을 가집니다. 그리고 Coroutine을 호출하거나 빠져나가거나 할 때마다 Context Switching이 일어납니다.
Context Switching을 하는 데에는 확실히 비용이 들어갑니다. 하지만 제 생각에 Coroutine에서 발생하는 Context Switching은 OS에서 실행할 Thread를 관리하는것처럼 Routine을 어떻게 실행시킬것인지 결정하는 일종의 관리 대상으로 봐야 한다고 생각합니다. 따라서 C++ Coroutine에서 발생하는 Context Switching 비용은 관리가 가능합니다. 필요없는 Context Switching은 문제가 되겠지만 그렇지 않은 Context Switching은 부담스럽다고 생각하지 않습니다. 그리고 특히 boost Context의 Context Switching은 현재의 컴퓨터 기준으로 보면 그렇게 부담스러운 작업은 아니라고 보여집니다. x86 CPU의 MSVC 환경에서 어떻게 이루어지는지 간단하게 보면 다음과 같습니다.
먼저 Context 정보를 저장하기 위해 fcontext_t라는 구조체를 사용합니다.


시작은 현재 Context 정보를 저장할 fcontext_t의 주소를 가져옵니다. 그리고 순서대로 EDI, ESI, EBX, EBP 레지스터를 저장합니다.

그리고 이어서 Switching 명령을 하기 전 원래 Routine에서의 ESP 레지스터를 저장하고, 마지막으로 Context Switching 시에 점프할 위치(호출한 다음 위치)를 저장합니다. 참고로 EIP는 실행될 다음 명령어의 주소를 가지는 레지스터로 점프할 위치로 점프 명령을 수행하면 EIP는 그 다음 명령어의 주소를 가지게 될 테니 따로 저장할 필요가 없습니다.
그리고 Switching할 Context의 정보를 가지고 있는 fcontext_t 주소를 가져옵니다. 마찬가지로 순서대로 EDI, ESI, EBX, EBP를 읽어옵니다.

boost Context는 FPU(부동 소수점 장치)를 보존할 것인지 여부를 설정할 수 있으며, 보존하는 경우 추가로 현재 FPU 정보를 저장하고 Switching할 Context의 FPU 정보를 읽어옵니다.

그리고 ESP 레지스터를 읽어오고, 점프할 위치를 읽어와서 ECX에 저장합니다.

마지막으로 jmp 명령어를 통해 Switching할 Context로 점프를 하는 것으로 대략적인 Context Switching 과정이 끝납니다.

이렇게 boost Context의 Context Switching 과정은 상당히 간단하게 처리되며, 비슷한 과정을 수행하는 Windows Fiber등과 비교했을때 훨씬 빠릅니다. boost Context의 설명페이지에서도 Context Switching 퍼포먼스 정보를 다음과 같이 표시하고 있습니다.

그럼 C++에서의 Coroutine은 아무런 문제가 없는 것인가?
그렇다고 해서 C++에서의 Coroutine을 아무렇게나 마구잡이로 만들어서 사용하는 것은 위험할 수 있습니다. C++에서 제대로 된 Coroutine을 구현하려면 한가지 문제가 있습니다. 바로 일정 크기의 Stack을 미리 할당해두어야 한다는 것입니다. 그리고 이렇게 할당된 Stack은 대부분의 경우 Stack 메모리를 모두 사용하였을때 늘릴 수 없습니다. 그래서 Coroutine을 처음 생성할 때에 충분히 큰 메모리를 할당해두고 사용하게 됩니다. Coroutine을 한두개 생성하는 정도라면 Thread처럼 1MB씩 Stack을 할당해서 사용해도 충분하겠지만 수백, 수천개씩 만들어야 하는 경우라면 메모리를 크게 할당할 수 없을 것입니다. 그래서 boost Coroutine의 Stack 메모리 기본값은 Windows인 경우 64kb로 되어있습니다. (64kb를 기본값으로 하는 이유는 최대한 작은 크기로 할당하면서 가장 효율적인 사이즈가 64kb이기 때문인 것 같습니다. 그 이유는 Allocation Granularity Boundary(할당 임계 영역) 때문인데, 이것은 메모리 할당의 시작 주소가 될 수 있는 기본 단위입니다. 따라서 64kb보다 더 작은 사이즈로 할당하는것은 메모리 조각화를 발생시키는 요인이 됩니다.)
Coroutine안에서 하는 일이 많다면 64kb보다 더 크게 할당해야 하는 경우도 생길것이고, 만약 Coroutine을 수만개까지 만들어야 하는 상황이 생긴다면 64kb라고 해도 부담될 수 있을 것입니다.
C++은 왜 Stack을 키우는 것이 어려울까?
메모리가 모자를 때 2배씩 재할당하는 방법은 흔히 메모리를 키워나가는 방식입니다. 간단하게 생각해보면 Stack Overflow가 발생하는 상황에 메모리를 재할당 받고 복사하는 방법으로 구현할 수 있을 것 같습니다. 이런 방식으로 동작하는 대표적인 예로 std::vector가 있습니다. std::vector의 경우 재할당을 받게 되면 객체의 복사생성자가 호출되며 복사가 이루어집니다.
그런데 이 방식에는 문제가 있습니다. C++ 객체 모델에서는 타입 메타 데이터 없이는 객체의 복사 생성자를 호출할 수 없고, 따라서 제대로 된 복사를 수행할 수 없습니다. 예를 들어 타입 메타 데이터 없이 memcpy같은 방식으로 복사를 수행하게 되면 Stack에 int a; int* b = &a; 이렇게 값이 올라가 있는 경우 재할당 후에 복사를 하고 나면 b는 다른 Stack 위를 가리키게 되는 문제가 발생합니다.
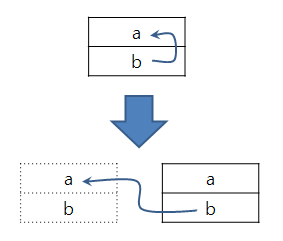
그렇다고 해서 Stack을 키우는 것이 아예 불가능한 것은 아닙니다. gcc 4.6의 경우 Split Stack 이라는 것을 지원합니다. 말 그대로 Stack을 분할하여 사용하는 것입니다.
일반적으로 함수 호출에 의해 Stack이 사용되는 과정은 호출 규약에 따라 조금씩 다르지만 일반적으로 다음과 같이 진행됩니다.
함수 호출을 몇 번 하는 간단한 코드를 예를 들어 설명해보도록 하겠습니다.

 |

testfunc()을 호출 하면 Stack에는 오른쪽 그림과 같이 인자값과 main()으로의 복귀 주소가 쌓이게 됩니다
 |  |
testfunc()으로 들어오면 이 위치에서 testfunc()이 사용하는 Stack의 크기만큼 Stack 영역을 확보합니다.
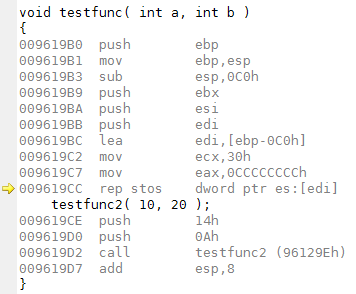 |  |
그리고 이 위치에서 확보된 Stack 영역을 초기화합니다.
 |  |
다시 testfunc2()를 호출하면 main()에서 testfunc()을 호출했을때와 마찬가지로 인자값과 testfunc()으로의 복귀 주소가 Stack에 쌓입니다.
 |  |
testfunc()처럼 testfunc2()로 들어오면 역시 사용할 크기만큼 Stack 영역을 확보합니다.
Split Stack은 함수가 호출된 시점에 해당 함수에서 사용되는 Stack의 크기만큼 확보할 때에 할당된 영역을 넘었는지 검사하고, 이때 할당된 영역을 넘었으면 새로운 Stack을 할당하여 호출에 의한 인자값 등 해당 함수에서 필요한 데이터들을 새로 할당받은 Stack에 복사하는 형태로 구현됩니다.

testfunc2()에서 사용할 크기만큼 Stack을 확보하려 할때에 만약 할당된 메모리가 부족하다면 여기서 판단할 수 있을 것입니다.

이때 새로운 메모리를 할당하고 해당 함수에서 사용할 데이터들만 새로운 Stack에 새로 쌓으면 문제없이 실행될 것 같습니다.
Split Stack은 함수 호출 규약의 종류가 많고 컴파일러 마다 다르게 처리되는 호출 규약도 존재하기 때문에 라이브러리 수준에서 구현하는것은 어렵습니다. 따라서 컴파일러에 의존적일수밖에 없습니다. 현재는 gcc 4.6 에서만 구현되어있고 LLVM쪽에서는 움직임이 있다고는 하지만 MS에서는 여러가지 문제로 인해 아무래도 지원하지 않을것 같습니다. 그리고 Split Stack은 구현 방식에 의해 어쩔 수 없이 미묘하게 성능 저하도 발생하는데 이러한 문제들로 인해 C++ 표준에 들어가는 것도 쉽진 않을것으로 예상됩니다.
boost Coroutine은 컴파일러가 Split Stack을 지원한다면 해당 기능을 사용할 수 있도록 작업되어있습니다. 현재 boost 1.54 버전에서는 gcc 4.7 이상 버전인 경우 Split Stack을 지원합니다.
결론
C++에서 Coroutine을 사용하는 경우에는 Context Switching 비용을 기반으로 Coroutine의 생성 및 관리를 하는 것 보다는 해당 Coroutine에서 사용되는 Stack 사이즈를 기반으로 관리를 해야 할 것 같습니다. 이러한 관리만 잘 된다면 C++에서도 마음놓고 Coroutine을 문제없이 사용할 수 있지 않을까요?
참조 :
WINDOWS VIA C/C++
http://www.boost.org/doc/libs/1_54_0/libs/coroutine/doc/html/index.html
http://blogs.msdn.com/b/oldnewthing/archive/2003/10/08/55239.aspx
http://www.sco.com/developers/devspecs/abi386-4.pdf
http://gcc.gnu.org/wiki/SplitStacks
도움을 주신 분들 :
박민철님(@summerlight00), Ted님(@booiljoung), 양승명님(@sequoiaxp), 이현정님(@Blackscomber)
ps. 잘못된 내용이 있는 경우 지적해주시면 수정하도록 하겠습니다!!